symjax.nn.losses¶
vae(x, x_hat, q_mean, q_cov[, z_mean, …]) |
N samples of dimension D to latent space in K dimension with Gaussian distributions |
vae_gmm(x, x_hat, z_mu, z_logvar, mu, …[, …]) |
N samples of dimension D to latent space of C sluters in K dimension |
vae_comp_gmm(x, x_hat, z_mu, z_logvar, mu, …) |
N samples of dimension D to latent space of I pieces each of C sluters in K dimension |
sparse_softmax_crossentropy_logits(p, q) |
Cross entropy loss given that \(p\) is sparse and \(q\) is the log-probability. |
softmax_crossentropy_logits(p, q) |
see sparse cross entropy |
sigmoid_crossentropy_logits |
|
accuracy(targets, predictions) |
classification accuracy. |
clustering_accuracy(labels, predictions, …) |
find accuracy of clustering based on intra cluster labels |
huber(targets, predictions[, delta]) |
huber loss (regression). |
explained_variance(y, ypred[, axis, epsilon]) |
Computes fraction of variance that ypred explains about y. |
hinge_loss(predictions, targets[, delta]) |
(binary) hinge loss. |
multiclass_hinge_loss(predictions, targets) |
multi-class hinge loss. |
squared_differences(x, y) |
elementwise squared differences. |
Detailed Descriptions¶
-
symjax.nn.losses.vae(x, x_hat, q_mean, q_cov, z_mean=None, z_cov=None, x_cov=None)[source]¶ N samples of dimension D to latent space in K dimension with Gaussian distributions
Parameters: - x (array) – should be of shape (N, D)
- x_hat (array) – should be of shape (N, D)
- q_mean (array) – should be of shape (N, K), infered mean of variational Gaussian
- q_cov (array) – should be of shape (N, K), infered log-variance of variational Gaussian
- z_mean (array) – should be of shape (K,), mean of z variable
- z_cov (array) – should be of shape (K,), logstd of z variable
-
symjax.nn.losses.vae_gmm(x, x_hat, z_mu, z_logvar, mu, logvar, logpi, logvar_x=0.0, eps=1e-08)[source]¶ N samples of dimension D to latent space of C sluters in K dimension
Parameters: - x (array) – should be of shape (N, D)
- x_hat (array) – should be of shape (N, D)
- z_mu (array) – should be of shape (N, K), infered mean of variational Gaussian
- z_logvar (array) – should be of shape (N, K), infered log-variance of variational Gaussian
- mu (array) – should be of shape (C, K), parameter (centroids)
- logvar (array) – should be of shape (C, K), parameter (logvar of clusters)
- logpi (array) – should be of shape (C,), parameter (prior of clusters) :param logvar_x: :param eps:
-
symjax.nn.losses.vae_comp_gmm(x, x_hat, z_mu, z_logvar, mu, logvar, logpi, logvar_x=0.0, eps=1e-08)[source]¶ N samples of dimension D to latent space of I pieces each of C sluters in K dimension
Parameters: - x (array) – should be of shape (N, D)
- x_hat (array) – should be of shape (N, D)
- z_mu (array) – should be of shape (N, I, K), infered mean of variational Gaussian
- z_logvar (array) – should be of shape (N, I, K), infered log-variance of variational Gaussian
- mu (array) – should be of shape (I, C, K), parameter (centroids)
- logvar (array) – should be of shape (I, C, K), parameter (logvar of clusters)
- logpi (array) – should be of shape (I, C), parameter (prior of clusters) :param logvar_x: :param eps:
-
symjax.nn.losses.sparse_softmax_crossentropy_logits(p, q)[source]¶ Cross entropy loss given that \(p\) is sparse and \(q\) is the log-probability.
The formal definition given that \(p\) is now an index (of the Dirac) s.a. \(p\in \{1,\dots,D\}\) and \(q\) is unormalized (log-proba) is given by (for discrete variables, p sparse)
\[\mathcal{L}(p,q)=-q_{p}+\log(\sum_{d=1}^D \exp(q_d))\]\[\mathcal{L}(p,q)=-q_{p}+LogSumExp(q)\]\[\mathcal{L}(p,q)=-q_{p}+LogSumExp(q-\max_{d}q_d)\]or by (non p sparse)
\[\mathcal{L}(p,q)=-\sum_{d=1}^Dp_{d}q_{d}+\log(\sum_{d=1}^D \exp(q_d))\]\[\mathcal{L}(p,q)=-\sum_{d=1}^Dp_{d}q_{d}+LogSumExp(q)\]\[\mathcal{L}(p,q)=-\sum_{d=1}^Dp_{d}q_{d}+LogSumExp(q-\max_{d}q_d)\]with \(p\) the class index and \(q\) the predicted one (output of the network). This class takes two non sparse vectors which should be nonnegative and sum to one.
-
symjax.nn.losses.accuracy(targets, predictions)[source]¶ classification accuracy.
It is computed by averaging the 0-1 loss as in
\[(Σ_{n=1}^N 1_{\{y_n == p_n\}})/N\]where \(p\) denotes the predictions. The inputs must be vectors but in the special case where targets is a vector but predictions is a matrix, then the argmax is used to get the real predictions as in
\[(Σ_{n=1}^N 1_{\{y_n == arg \max p_{n,:}\}})/N\]Parameters: - targets (1D tensor-like) –
- predictions (tensor-like) – it can be a \(2D\) matrix in which case the
argmaxis used to get the prediction
Returns: Return type: tensor-like
-
symjax.nn.losses.clustering_accuracy(labels, predictions, n_clusters)[source]¶ find accuracy of clustering based on intra cluster labels
This accuracy allows to quantify the ability of a clustering algorithm to solve the clustering task given the true labels of the data. This functions finds for each predicted cluster what is the most present label and uses it as the cluster label. Based on those cluster labels the accuracy is then computed.
Args:
- labels: 1d integer Tensor
- the true labels of the data
- predictions: 1d integer Tensor
- the predicted data clusters
- n_clusters: int
- the number of clusters
-
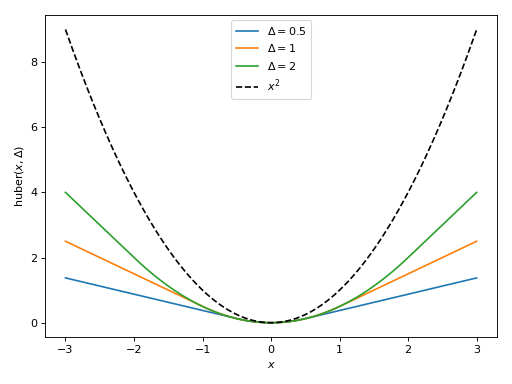
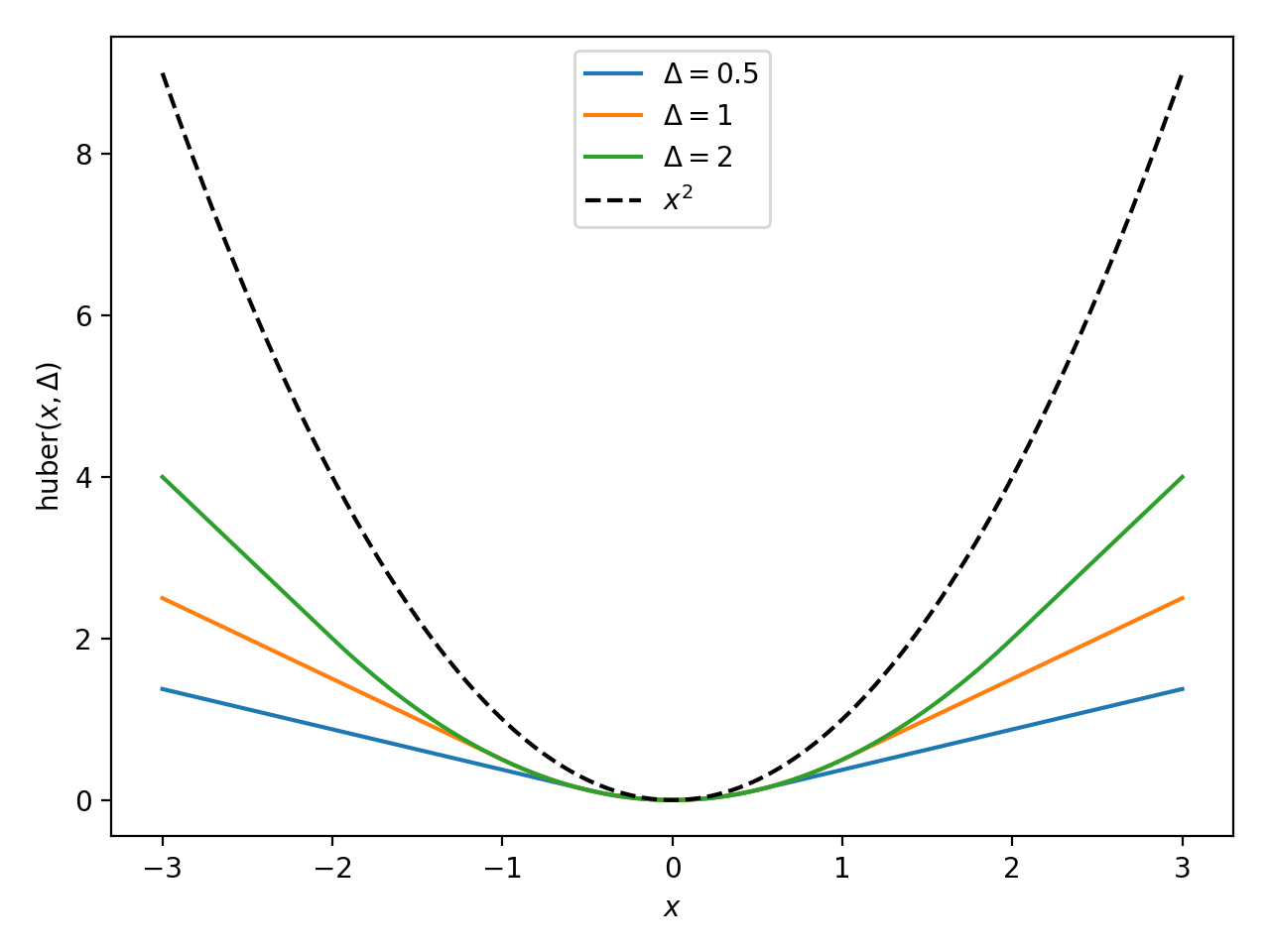
symjax.nn.losses.huber(targets, predictions, delta=1.0)[source]¶ huber loss (regression).
For each value x in error=targets-predictions, the following is calculated:
- \(0.5 × x^2\) if \(|x| <= Δ\)
- \(0.5 × Δ^2 + Δ × (|x| - Δ)\) if \(|x| > Δ\)
leading to
(Source code, png, hires.png, pdf)
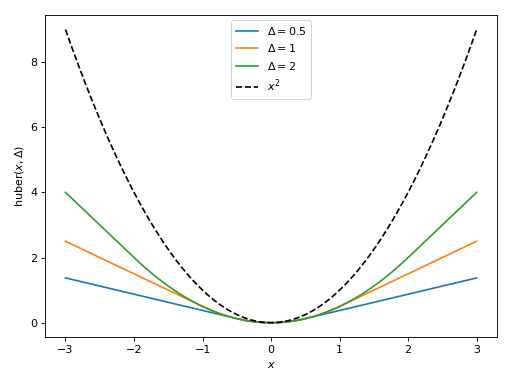
Parameters: - targets – The ground truth output tensor, same dimensions as ‘predictions’.
- predictions – The predicted outputs.
- delta (Δ) – float, the point where the huber loss function changes from a quadratic to linear.
Returns: loss float, this has the same shape as targets
{kind=link}
{kind=link}
-
symjax.nn.losses.explained_variance(y, ypred, axis=None, epsilon=1e-06)[source]¶ Computes fraction of variance that ypred explains about y. The formula is
\[1 - Var[y-ypred] / Var[y]\]and in the special case of centered targets and predictions it becomes
\[1 - \|y-ypred\|^2_2 / \|y\|_2^2\]hence it can be seen as an :math:`ℓ_2’ loss rescaled by the energy in the targets.
interpretation:
- ev=0 => might as well have predicted zero
- ev=1 => perfect prediction
- ev<0 => worse than just predicting zero
- y: Tensor like
- true target
- ypred: Tensor like
- prediction
- axis: integer or None (default=None)
- the axis along which to compute the var, by default uses all axes
- epsilon (ϵ): float (default=1e-6)
- the added constant in the denominator
\[1 - Var(y-ypred)/(Var(y)+ϵ)\]This is not a symmetric function
-
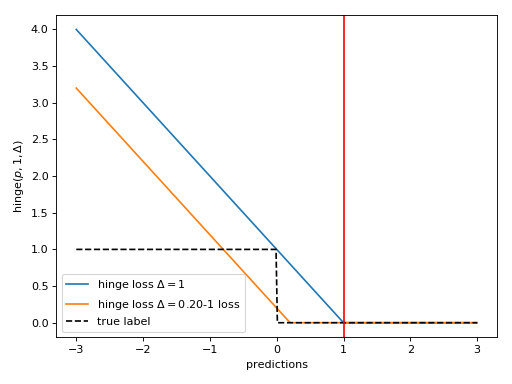
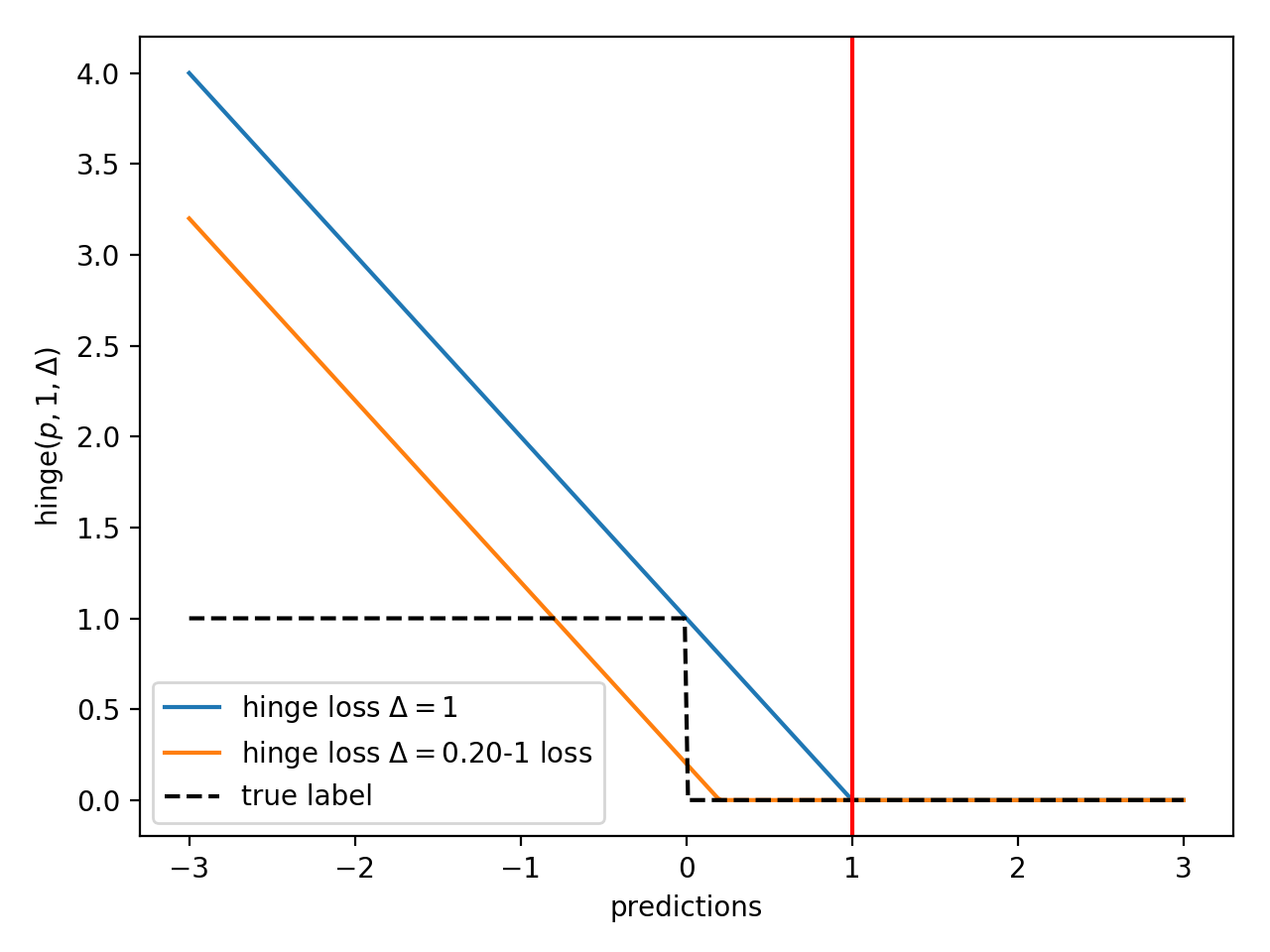
symjax.nn.losses.hinge_loss(predictions, targets, delta=1)[source]¶ (binary) hinge loss.
For an intended output \(t = ±1\) and a classifier score \(p\), the hinge loss is defined for each datum as
\[\max ( 0 , Δ − t p)\]as soon as the loss is smaller than \(Δ\) the datum is well classified, however margin is increased by pushing the loss to \(0\) hence \(Δ\) is the user-defined prefered margin to reach. In standard SVM \(Δ=1\) leading to
(Source code, png, hires.png, pdf)
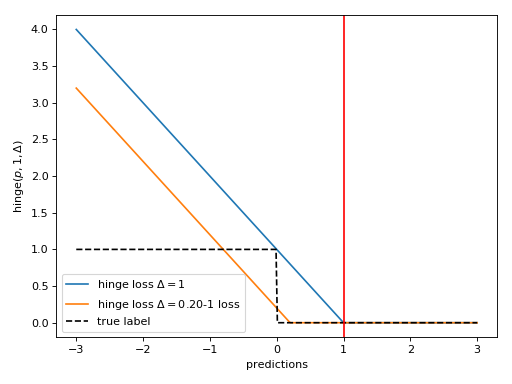
Note that \(p\) should be the “raw” output of the classifier’s decision function, not the predicted class label. For instance, in linear SVMs, \(p = <w, x> + b\) where ( \(w , b\) are the parameters of the hyperplane and \(x\) is the input variable(s).
Parameters: - predictions (1D tensor) – prediction of the classifier (raw,)
- targets (1D binary tensor with values in \(t\in\{-1,1\}\).) –
Returns: An expression for the item-wise hinge loss
Return type: 1D tensor
Notes
This is an alternative to the categorical cross-entropy loss for classification problems
{kind=link}
{kind=link}
-
symjax.nn.losses.multiclass_hinge_loss(predictions, targets, delta=1)[source]¶ multi-class hinge loss.
\[L_i = \max_{j ≠ t_i} (0, p_j - p_{t_i} + Δ)\]Parameters: - predictions (2D tensor) – Predictions in (0, 1), such as softmax output of a neural network, with data points in rows and class probabilities in columns.
- targets (Theano 2D tensor or 1D tensor) – Either a vector of int giving the correct class index per data point or a 2D tensor of one-hot encoding of the correct class in the same layout as predictions (non-binary targets in [0, 1] do not work!)
- delta (scalar, default 1) – The hinge loss margin
Returns: An expression for the item-wise multi-class hinge loss
Return type: Theano 1D tensor
Notes
This is an alternative to the categorical cross-entropy loss for multi-class classification problems